Transformers: The Model Architecture Revolutionizing AI
Transformers have emerged as one of the most influential innovations in deep learning. Originally introduced by Google Researchers in 2017 via the seminal “Attention is All You Need” paper (https://arxiv.org/abs/1706.03762) for natural language processing (NLP) tasks like translation and text generation, transformers are also driving advances across computer vision, speech recognition, and other AI domains. Transformers have catalyzed major advances in artificial intelligence, particularly through powering large language models (LLMs) and foundation models. This enabled a scale-up in model size unprecedented in deep learning. Transformers gave rise to large language models like GPT (Generative Pre-trained Transformer) and one chatbot application that have taken the world by storm: OpenAI’s ChatGPT. But what exactly are transformers and how do they work? In this post, I’ll unpack the transformer architecture at an intuitive level.
Attention is Worth a Contextualized Thousand Words
Transformers lead a new era of contextual sequence modeling through their pioneering attention mechanisms. For complex language tasks, transformers capture the interdependencies between words in a contextualized manner that recurrent models cannot. While recurrent neural networks (RNNs) process sequences sequentially, transformers process the entire sequence at once in parallel.
![]()
![]()
Image source: http://peterbloem.nl/blog/transformers
The attention mechanism creates direct connections between all inputs in a sequence, allowing the model to focus on the most relevant parts as needed. This is similar to how we pay visual attention to certain regions in an image. Human comprehension integrates context fluidly. When reading text, we interpret the meaning of each word in relation to the surrounding words and phrases. Transformers mimic this contextual processing through multi-headed self-attention. The model learns contextual relationships between all words in a passage, not just sequential dependencies. This flexible contextual processing provides advantages for real-world NLP applications. In translation, transformers excel at carrying over contextual meaning from the source to target languages, something lost with RNNs. The model dynamically attends to the most relevant context to produce fluent translations. Similarly for text summarization, the transformer can pinpoint the most salient points in a document by modeling the full context. This mirrors human understanding of picking out key ideas from contextual information. Overall, by incorporating contextual processing with parallel attention, transformers achieve state-of-the-art results on many language tasks. Their ability to model soft contextual connections matches human-level language understanding better than rigid sequential modeling. Transformers usher in a new contextual paradigm for natural language processing
Attention: Finding What Matters
At its core, attention is about focusing on what’s relevant. Just like we pay visual attention to certain objects in a scene, attention in deep learning models lets them focus on pertinent parts of their input.
But how does attention actually work? The first step is to calculate similarity scores between a query and a set of key-value pairs.
\[x_i = \alpha (q, k_i)\]The query $q$ encapsulates what the model wants to focus on. The keys $k$ represent candidate relevant inputs. These similarity scores are calculated using functions like the scaled dot product. This determines how closely the query aligns with each key based on their vector representations. Keys $k_i$ with higher dot products have greater relevance to the query $q$.
The Intuition Behind Self-Attention
Self-attention, the core innovation behind transformers, is conceptually simple. For each input, it calculates attention scores against all other inputs based on their relatedness. Highly related inputs get higher scores. These scores determine a weighted sum representing the relevant context for each input. By focusing on the most important parts of the sequence, self-attention provides the right contextual representation to encode the inputs effectively. In self-attention, the queries, keys and values all come from the same place - different positions of the input sequence. This allows relating different parts of the sequence to each other. For example, a token could attend to previous tokens that provide context for understanding it.
Output Scoring
Next, a softmax layer turns the scores into normalized probabilities. This assigns likelihood values to each input indicating how pertinent it is given the query. The probabilities are used to calculate a weighted sum of the values - placing more emphasis on relevant inputs.
\[y_1, \cdots, y_n = softmax (x_i, \cdots, x_n)\]Let’s transform the above equation into a more concrete variables flowing inside the Transformers. Practically, we pack multiple query vectors together into a matrix $Q$. The key vectors $K$ and value vectors $V$ are also stacked together into matrices. This allows us to compute the attention function for the full set of queries efficiently in parallel. Specifically, we take the dot product of the query matrix $Q$ with the transpose of the key matrix $K$ to generate the attention scores. This results in each query vector being matched with all the key vectors. The attention score matrix is then scaled and normalized using the softmax function.
Finally, the normalized attention score matrix is multiplied with the value matrix $V$ to generate the output matrix. This output matrix contains the weighted sum of values for each query, where the weight assigned to each value is determined by the attention scores calculated. In this way, stacking multiple queries, keys and values into matrices allows the attention function to be computed for the full set in a highly parallelized implementation. The matrix calculations help attend to all the relevant keys for each query simultaneously.
Mathematically, the above processes are represented as follows:
\[Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V\]Code Snippet
For some curious technical readers, let me put the code snippets for the attention function as follows.
# Attention implementation (Scaled Dot Product) using Pytorch library.
import torch
import torch.nn.functional as F
def attention(query_mat, key_mat, value_mat):
# Calculate dot product between query and keys
key_dim = query_mat.size(-1)
relevance_scores = torch.matmul(query_mat, key_mat.transpose(-2, -1)) / math.sqrt(key_dim)
# Convert scores to probabilites
attention_weights = F.softmax(relevance_scores, dim=-1)
# Calculate weighted average of values
attention_output = torch.matmul(attention_weights, value_mat)
return attention_output, attention_weights
Multi-Headed Attention: A Key Building Block of Transformers
One of the most important attentional components is multi-headed attention. This allows the model to jointly attend to information from different representation subspaces at different positions. At its core, multi-headed attention involves projecting the inputs into multiple “heads”, where each head represents a different attentional representation. Within each head, scaled dot-product attention is applied between the query, key, and value vectors. This produces an output for each head.
The different heads are then concatenated and projected again to the final values. This multi-headed approach provides the benefits of both summarizing the inputs and focusing on different positional and representational relationships. Specifically, multi-headed attention is used in three key places within the transformer architecture:
- Encoder Self-Attention: The encoder queries, keys, and values all come from the encoder’s input. This allows each position to attend to all other positions and capture contextual relationships.
- Decoder Self-Attention: The decoder queries, keys, and values come from the previous decoder outputs. Masking prevents leftward information flow and maintains auto-regressive order.
- Encoder-Decoder Attention: The decoder queries come from the decoder, while the encoder keys and values are projected to the decoder. This bridges both components.
By employing multi-headed attention, transformers can jointly process information at different positions from different representational subspaces. This provides expressive power to learn complex functions mapping input sequences to output sequences. Multi-headed attention has been a crucial innovation for creating effective deep attentional models.
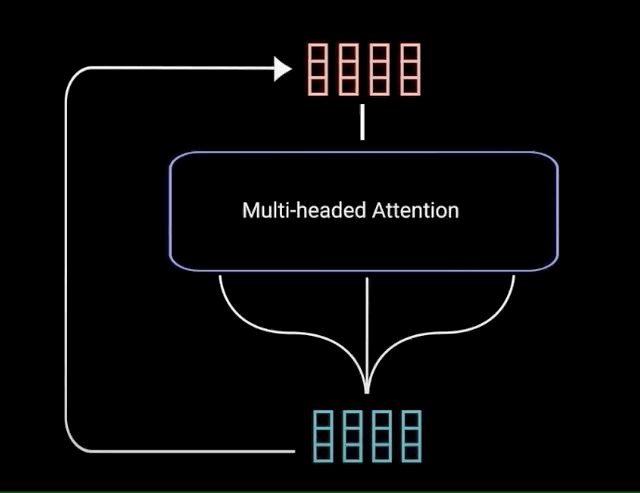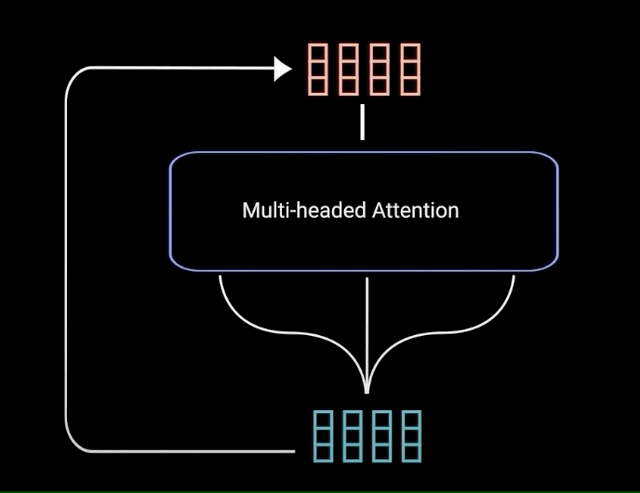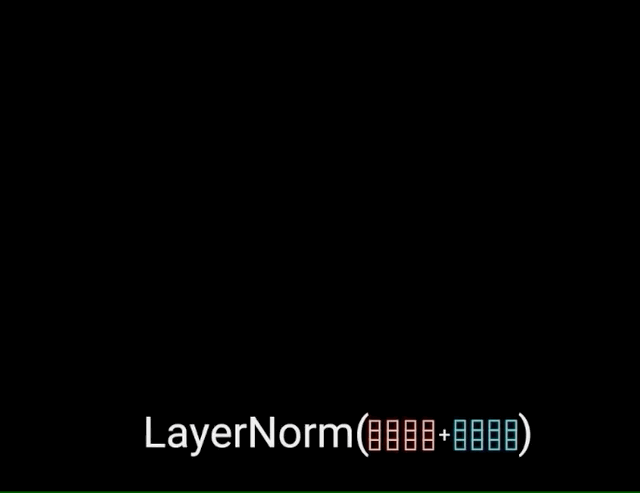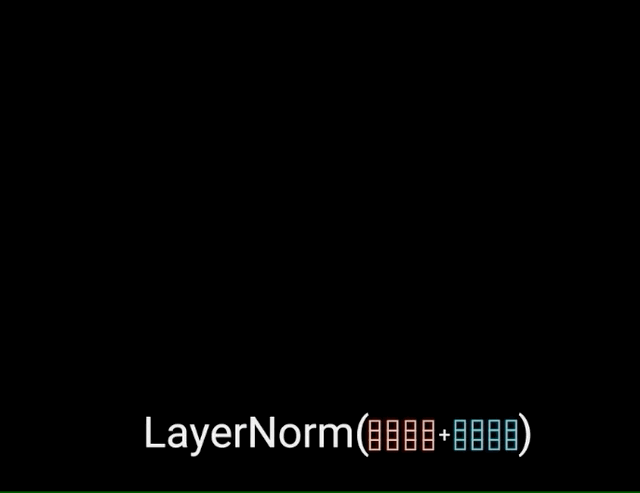

Image source: https://yashugupta-gupta11.medium.com/in-and-out-of-transformers-attention-is-all-you-need-deep-nlp-horse-260b97988278
Behind the Magic - A High-Level View
Fundamentally, the transformer consists of an encoder and a decoder. The encoder maps the input to a rich, contextual representation. The decoder then uses this representation to generate the output. In NLP, the encoder operates on the input text while the decoder generates the translated or summarized text. For image processing, the encoder processes the input image and the decoder reconstructs or generates it. The encoder itself has two components - a self-attention layer and a feedforward network. Self-attention identifies important context across the entire input. The feedforward network further refines this representation. The decoder also has a cross-attention layer that focuses on relevant parts of the encoder output. This allows the decoder to produce the output while looking at the appropriate input context.
 Image source: https://alvinntnu.github.io/NTNU_ENC2045_LECTURES/temp/dl-seq-to-seq-types.html
Image source: https://alvinntnu.github.io/NTNU_ENC2045_LECTURES/temp/dl-seq-to-seq-types.html
Simpler Than It Looks!
While transformers enable complex modeling, the implementation involves simple, repeated blocks of self-attention, cross-attention and feedforward layers. This repetitive structure makes transformers easy to optimize and scale to huge datasets across diverse domains.
The self-attention layer connects different positions of the input sequence to build a representation that incorporates contextual information from the full sequence. The feedforward network processes each position identically to extract features.
During training, the input data is converted to embeddings which are fed to the encoder. The encoder output and target tokens are given as input to the decoder, also composed of similar blocks. The decoder predicts the next token, and the loss between predicted and actual target tokens is used to update the model weights.
During inference, the trained encoder processes the input sequence to generate encoder representations. The trained decoder takes these representations and predicts the output sequence token by token in an autoregressive manner. The self-attention and feedforward layers in the Transformer enable modeling both local and global dependencies.
In this way, the Transformer architecture processes sequences in parallel to learn contextual representations during training, and generates outputs autoregressively during inference. The key components are self-attention layers to model dependencies and feedforward layers for feature extraction.