The Evolution of Transformers into GPT - How AI is Rewriting Itself
Transformers have taken the world by storm in particular after the introduction of chatGPT, an AI chatbot application powered other than nothing but Transformers. First introduced in 2017, these novel neural network architectures rapidly became the dominant approach across natural language processing and computer vision.
At the heart of Transformers are self-attention mechanisms that allow modeling long-range dependencies in sequences. For a sequence of word inputs $x_1, x_2, …, x_n$, they are being treated as query $Q$, key $K$, and value $V$ within self-attention mechanism that calculates attention scores between each pair of words:
\[Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V\]where $Q$ and $K$ are learned projection matrices that map the inputs to a queries and keys vector space. This gives a matrix of attention scores used to aggregate the values, enabling modeling context from the entire sequence.
For the readers who want to understand the gist of Transformers on the intuition and a glimpse of technical level, please read my previous notes: https://rasyaq.github.io/2022/07/10/Understanding-Transformers.html
In 2018, researchers at OpenAI took Transformers to the next level with the Generative Pre-trained Transformer (GPT). GPT was pre-trained on a massive text corpus to learn universal language representations that could then be fine-tuned for downstream tasks.
GPT pioneered the idea of self-supervised pre-training in NLP. By pre-training on unlabeled text, GPT learns relationships between words and how language flows naturally. This general linguistic knowledge can then be transferred and adapted for specific applications.
Successive GPT models have followed a trend of scaling up size and training data. GPT-2 stunned the AI community by generating coherent paragraphs of text given just a sentence prompt. GPT-3 took it even further, using 175 billion parameters trained on unfathomable amounts of text data scraped from the Internet.
GPT-3 displays eerily human-like writing abilities, even though it has no understanding of the content it generates. Its capabilities and potential societal impacts have sparked heated debate.
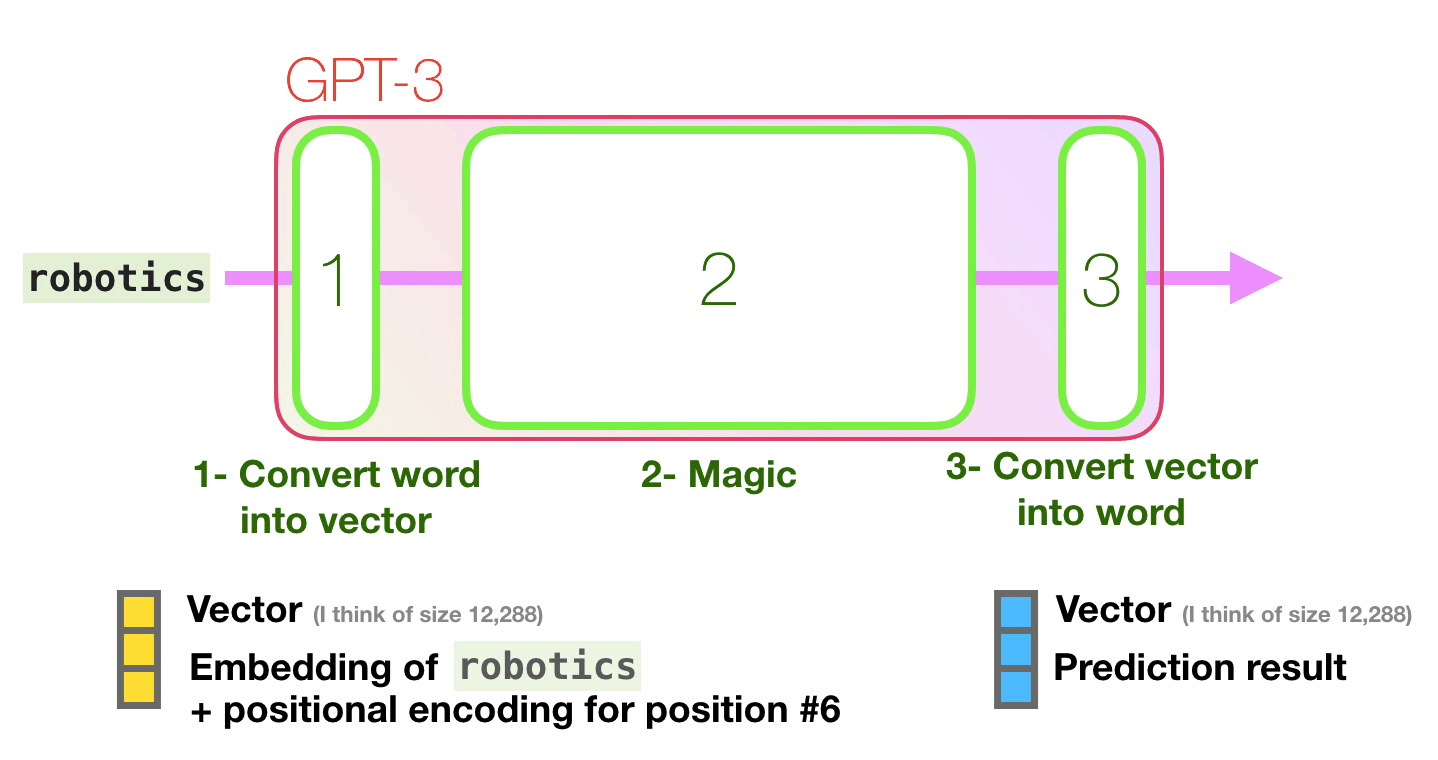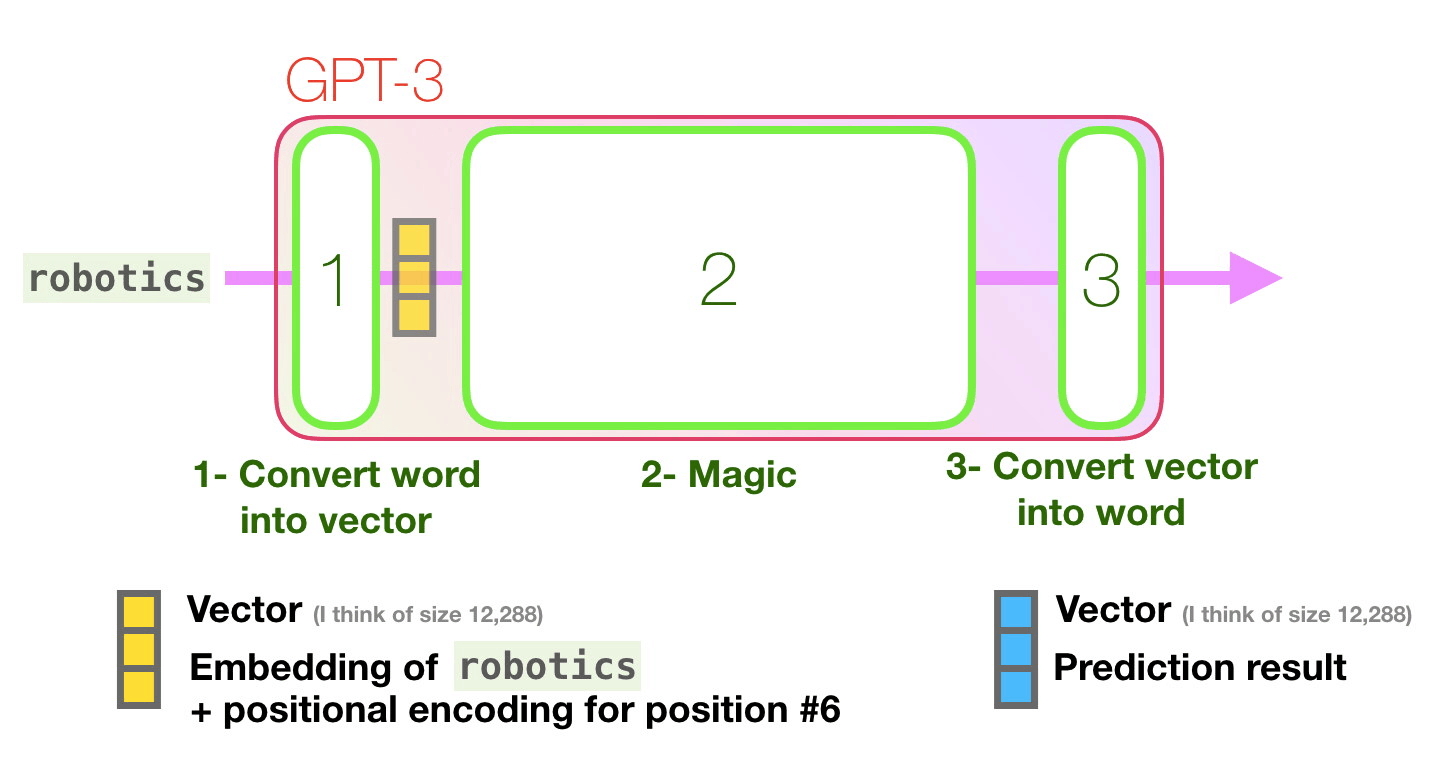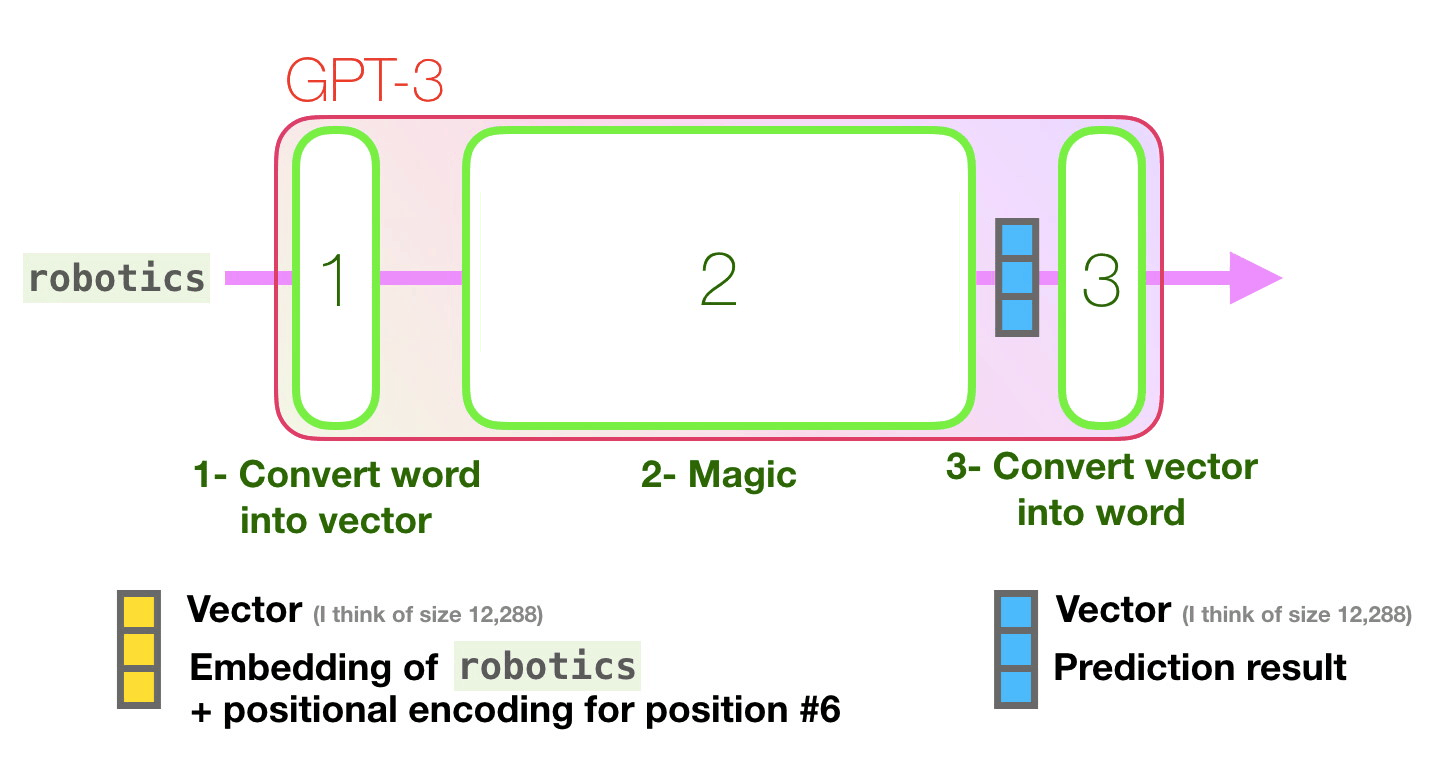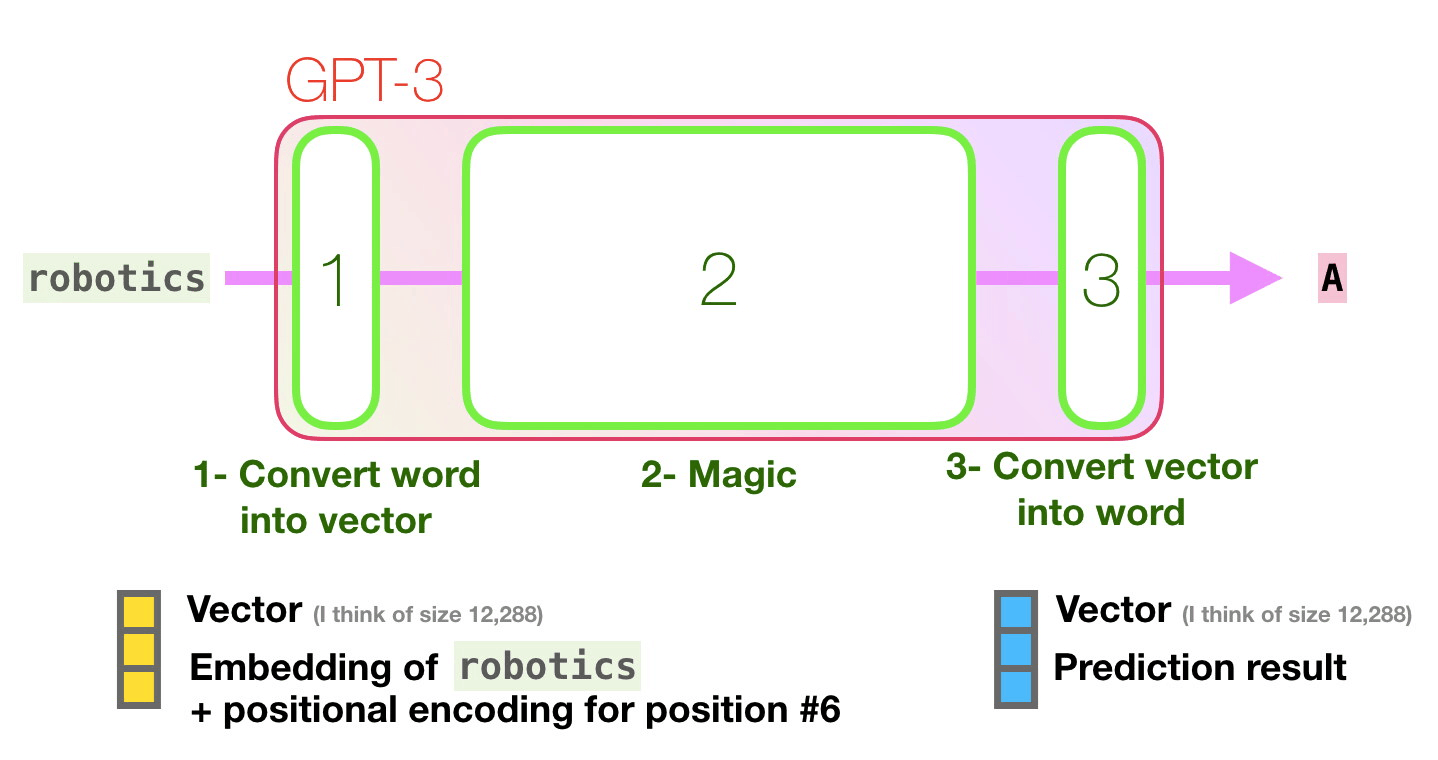
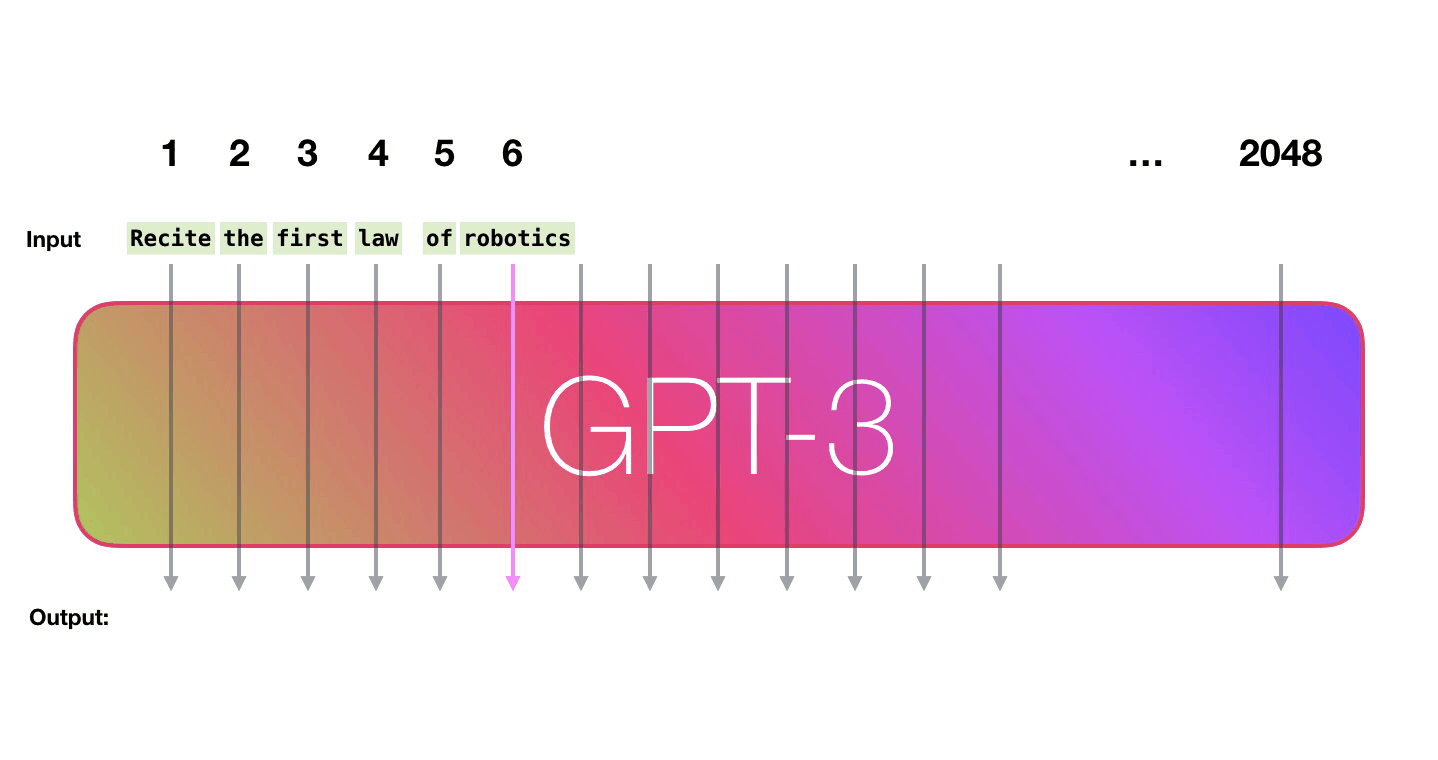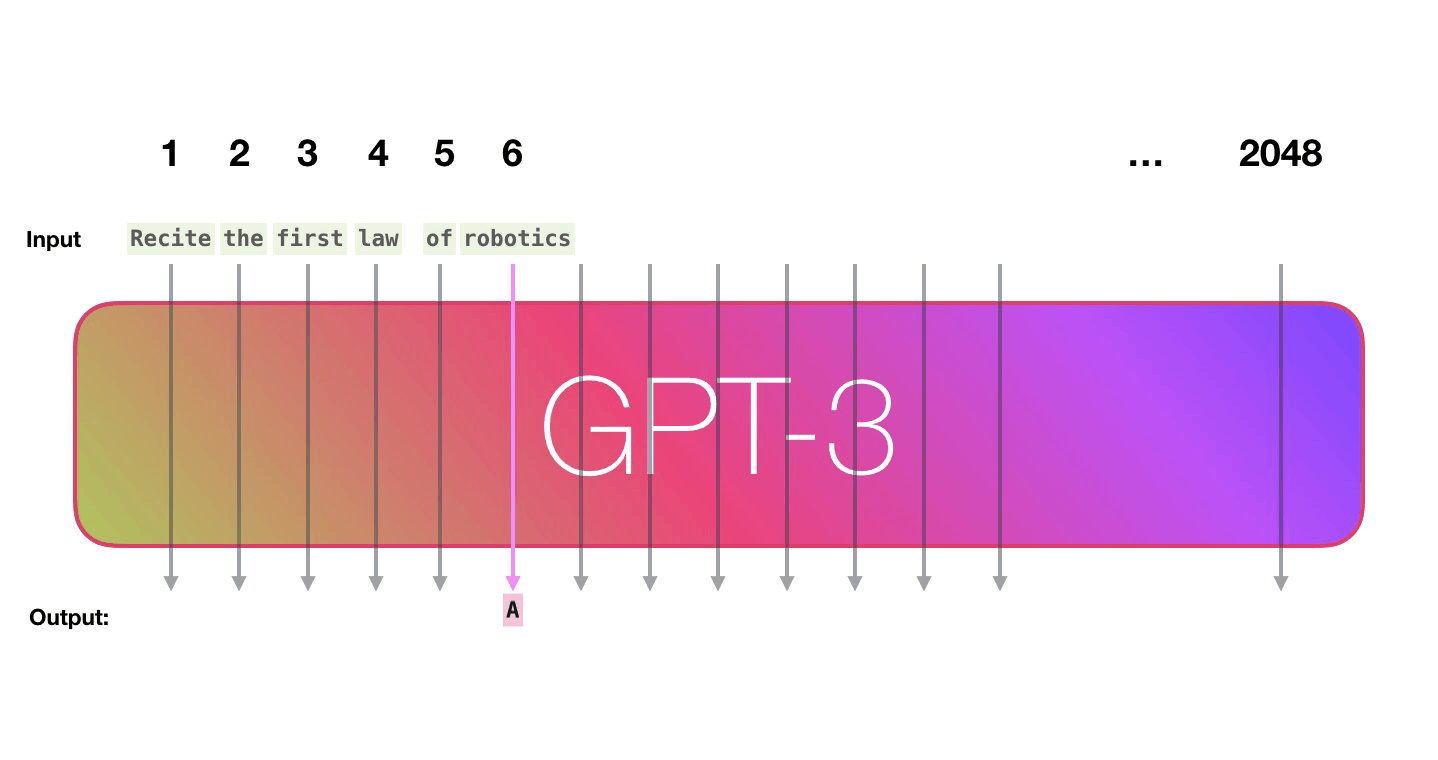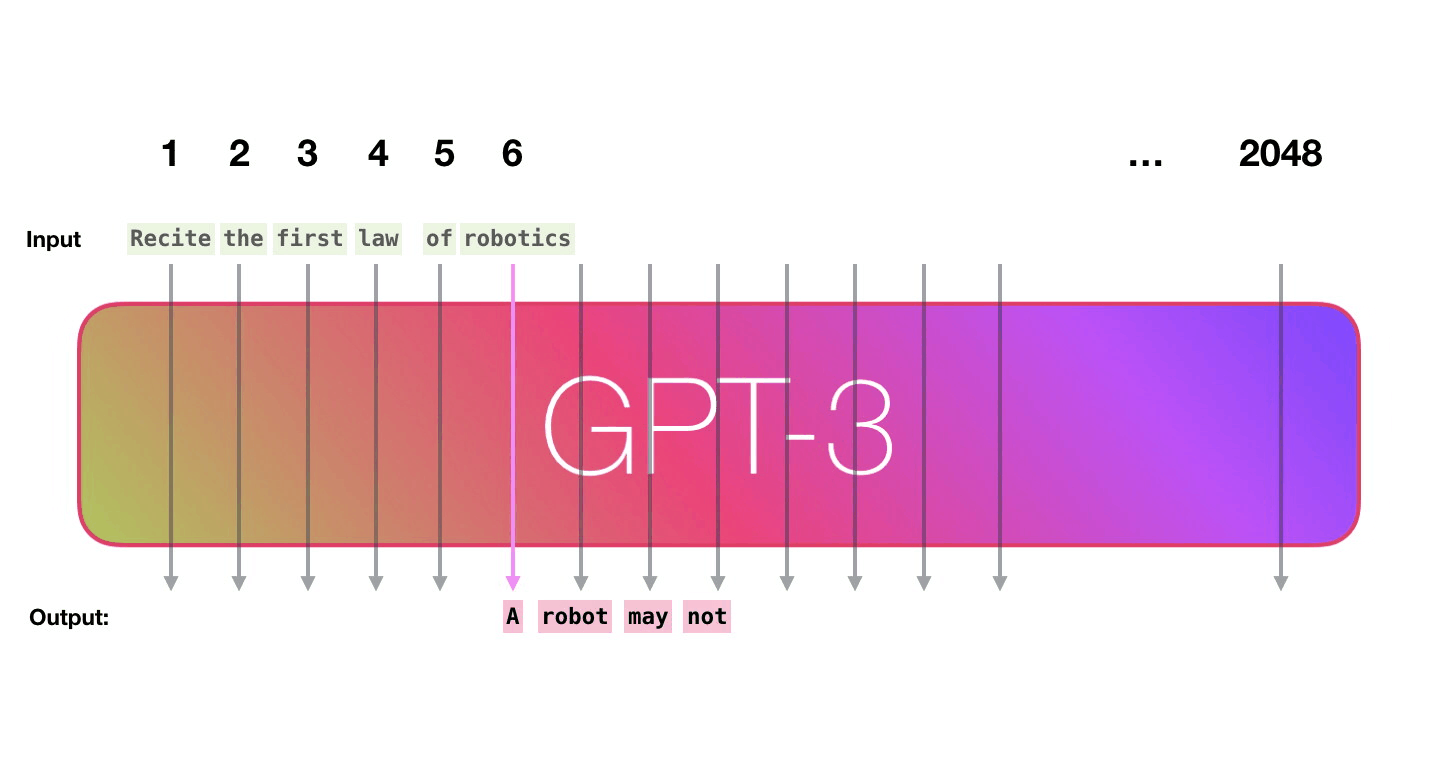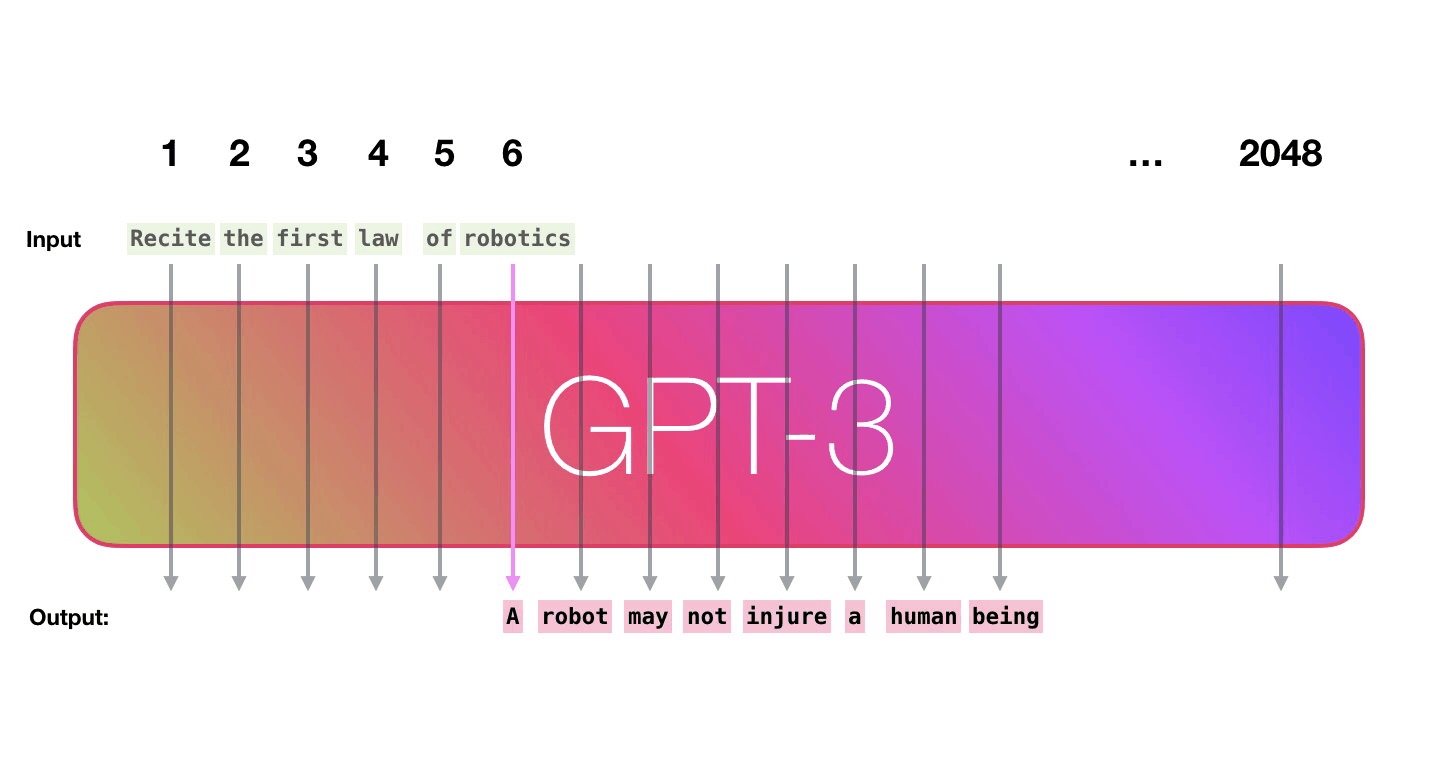
Image source: http://jalammar.github.io/how-gpt3-works-visualizations-animations/
Meanwhile, the GPT approach keeps spreading to new domains like computer vision and multimodal applications. Models like DALL-E 2 can generate realistic images from text captions. The line between AI creativity and mimicking human output continues to blur.
The journey from Transformers to GPT illustrates an acceleration in AI capabilities fueled bycombining generalizable architectures with vast computational resources and data.
For technical interested readers, let me show the key aspects in code for GPT:
import torch
import torch.nn as nn
# Attention and multi-headed attention
class Attention(nn.Module):
def __init__(self, emb_dim):
super().__init__()
self.query = nn.Linear(emb_dim, emb_dim)
self.key = nn.Linear(emb_dim, emb_dim)
self.value = nn.Linear(emb_dim, emb_dim)
self.sqrt_emb_dim = emb_dim ** 0.5
def forward(self, x):
queries = self.query(x)
keys = self.key(x)
values = self.value(x)
weights = torch.bmm(queries, keys.transpose(1,2)) / self.sqrt_emb_dim
attn_outputs = torch.bmm(weights, values)
return attn_outputs
class MultiHeadAttention(nn.Module):
def __init__(self, emb_dim, num_heads):
super().__init__()
self.heads = nn.ModuleList([Attention(emb_dim) for _ in range(num_heads)])
self.linear = nn.Linear(emb_dim, emb_dim)
def forward(self, x):
attn_outputs = torch.cat([h(x) for h in self.heads], dim=-1)
aggregated_outputs = self.linear(attn_outputs)
return aggregated_outputs
# Model
class GPT(nn.Module):
def __init__(self, vocab_size, emb_dim, n_layers):
super().__init__()
self.embeddings = nn.Embedding(vocab_size, emb_dim)
self.layers = nn.ModuleList([nn.Linear(emb_dim, emb_dim) for _ in range(n_layers)])
self.lm_head = nn.Linear(emb_dim, vocab_size)
def forward(self, x):
h = self.embeddings(x)
for layer in self.layers:
h = layer(h)
logits = self.lm_head(h)
return logits
# Training
model = GPT(vocab_size=5000, emb_dim=64, n_layers=2)
for inputs, targets in dataloader:
logits = model(inputs)
loss = nn.functional.cross_entropy(logits.reshape(-1, 5000), targets.reshape(-1))
loss.backward()
optimizer.step()
optimizer.zero_grad()
The code defines the building blocks for a Transformer-based generative pre-trained language model like GPT. It first defines an Attention module, which takes input embeddings and applies query, key and value transformations to compute scaled dot-product attention weights. This allows the model to attend to different parts of the input sequence. The MultiHeadAttention module extends this by having multiple parallel Attention heads. Their outputs are concatenated and projected for the final multi-headed attention outputs. This provides multiple “representation subspaces” for the model to attend over. The GPT model brings this together with an embedding layer, stacked self-attention layers, and a final classifier head. The embeddings convert token IDs to dense vectors. The self-attention layers process the input sequence using multi-headed self-attention. This allows modeling long-range dependencies in text. Finally the classifier predicts token probabilities for the next word, enabling autoregressive language modeling. During pre-training, this model is trained on large corpora to maximize likelihood of the next word given all previous context. This teaches broad linguistic knowledge in a self-supervised fashion. The pre-trained model can then be fine-tuned for downstream NLP tasks by adding task-specific heads. So in summary, the Transformer architecture here provides means for generative pre-training to learn powerful language representations from unlabeled text in a scalable way.
Transformers utilize multi-headed self-attention to capture long-range dependencies in text. For pre-training, the model is shown vast volumes of text data without any explicit task. The goal is to predict the next token based on context derived from self-attention across all positions. This allows the model to learn the fundamental structure of language from the ground up in a self-supervised manner. The pre-trained model can then be fine-tuned for downstream NLP tasks by adding task-specific classifier heads. Pre-training provides broad linguistic context about semantics, syntax, entities, topics etc. Fine-tuning then adapts this general knowledge to specialized datasets. This transfer learning approach is the key innovation of GPT-style generative pre-training.
Imagine teaching a bright young student to become a great writer. First, you provide diverse materials for them to read extensively. Through reading copious books, articles, stories, and more, they incrementally learn the nuances of language and writing. Next, you give writing exercises to practice generating original sentences and passages. Gradually, their skills improve to write coherently on any topic. This human learning process is analogous to how Transformers work in GPT-style pre-training. By processing massive textual corpora, Transformers acquire general linguistic intelligence. Fine-tuning then trains them to generate specific types of text. The scale of pre-training determines model capability, much like how extensively reading great works molds a skilled writer.
GPT-style pre-training has produced Transfomers with astonishing natural language abilities. For instance, GPT-3 trained on hundreds of billions of words can generate remarkably human-like text across a diverse range of styles and topics. This emergent intelligence comes purely from self-supervised learning, without any hand-engineered rules or labels. Such models have reached new milestones in automated reasoning, question answering, summarization, translation, and other language generation tasks. The key innovation of GPT pre-training is providing broad world knowledge before task-specific fine-tuning. This enables models like GPT-3 to attain strong performance on downstream tasks using only in-context learning on small datasets, without any gradient updates. The scalability of self-supervised learning suggests exciting future applications as model size and data continue growing.